

"인공지능은 마치 쉐프가 재료를 분해 후 재조합하듯이 한글 이해해"
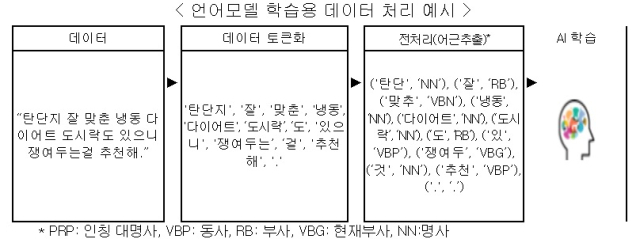
인공지능(AI)이 한국어를 이해하는 과정은 마치 요리사가 음식을 하는 과정과 비슷하다. 요리사가 재료를 손질해 분해한 뒤 재조합하면서 음식을 만들게 되는데, 한국어도 글자를 작은 단위인 '토큰'으로 나누고 인공지능이 이 패턴을 인식해 재조합하는 과정에서 학습한다.
8일 한국지능정보사회진흥원(NIA)에 따르면 인공지능이 한국어를 이해하는 과정은 자연어 처리(NLP)와 딥러닝(심층학습) 등 크게 두 가지의 과정으로 나뉜다.
자연어 처리는 컴퓨터가 인간의 언어를 이해하고 처리할 수 있게 도와주는 분야이다. 글자 자료(텍스트 데이터)를 분리하고 형태소 분석기를 거쳐 문법 구조와 어휘의 의미를 이해하는 데 목적이 있다.
딥러닝은 그다음 단계에서 글자의 맥락을 이해하는 데 중요한 역할을 한다. 다양한 목적과 맥락을 가진 문단, 문장, 단어들 간의 복잡한 패턴을 파악하는 것이다.
한국어는 영어와 어순이 다르고 화자의 섬세한 맥락을 풍부하게 표현할 수 있다. 이 때문에 한국말은 끝까지 들어봐야 결론을 안다는 말이 나온 것이다. 이처럼 풍부한 표현을 제대로 학습하기 위해서는 다양한 형태의 대규모 패턴 예시, 즉 인공지능 학습용 한국어 데이터를 구축하여 인공지능에게 학습시켜야 한다.
인공지능은 ▷획득 ▷정제 ▷가공 ▷검수 과정으로 데이터를 학습하게 된다. 이 과정에서 얼마나 고품질의 데이터를 준비했느냐에 따라 한국어 이해 수준이 달라진다.
신신애 NIA 지능데이터본부 본부장은 "인공지능 학습용 데이터를 구축하는 과정은 AI 모델 학습을 위한 코딩 과정과 다소 차이가 있다"며 "그러나 AI 모델이 한국어를 어떻게 학습하는지 깊이 있는 이해가 있어야 AI 모델에 최적화된 한국어 데이터를 설계하고 구축할 수 있다"고 했다.




